Celestia
Key Takeaways
- Celestia is a modular blockchain platform that provides sovereignty, customizability, and decentralization to its users.
- Celestia's data availability layer provides two key features: data availability sampling (DAS) and Namespaced Merkle trees (NMTs).
- Celestia offers a unique architecture that allows developers to focus on the core logic of their applications while Celestia handles the consensus and data availability layers.
- Celestia has use cases in OP-Stack, Rollkit, and Sovereign Labs.
1. Overview
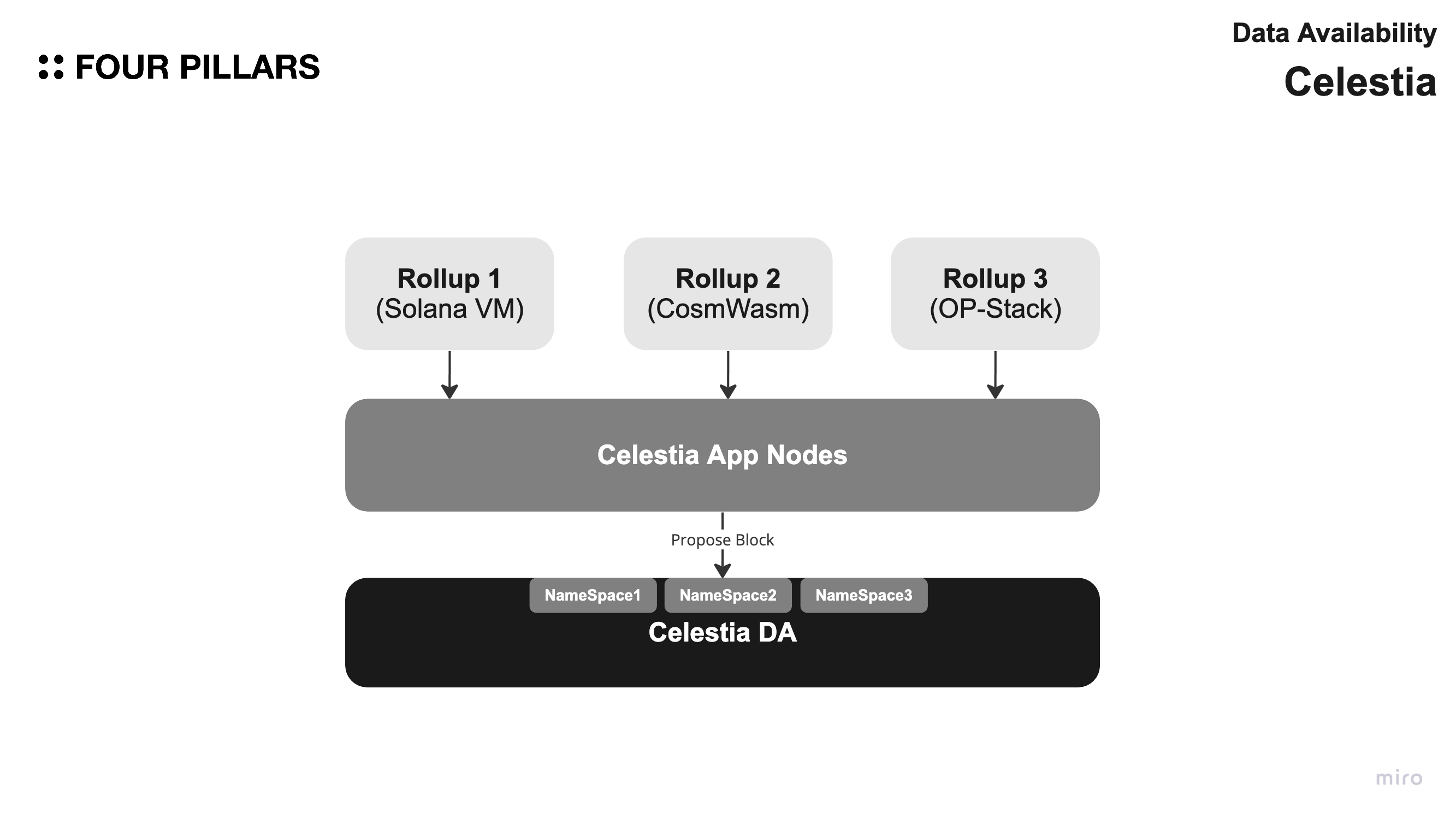
Celestia is a modular blockchain platform that aims to provide sovereignty, customizability, and decentralization to its users. It offers a unique architecture that allows developers to focus on the core logic of their applications while Celestia handles the consensus and data availability layers.
2. Data Availability
2.1 Technology
Celestia's data availability layer provides two key features: data availability sampling (DAS) and Namespaced Merkle trees (NMTs). Both features are novel blockchain scaling solutions: DAS enables light nodes to verify data availability without needing to download an entire block, and NMTs enable execution and settlement layers on Celestia to download transactions that are only relevant to them.
2.1.1 DAS
DAS enables light nodes to verify data availability without needing to download an entire block.
Data Availability Sampling (DAS) is a key part of the blockchain structure, especially for light nodes. Celestia uses a 2D Reed-Solomon encoding scheme to encode the block data and safeguard its accuracy. The block data is split into smaller sections, combined with parity data, and organized into a 2k × 2k matrix. Reed-Solomon encoding is applied multiple times to ensure data fidelity, and separate Merkle roots are calculated for the rows and columns of the extended matrix to derive the block data commitment in the block header. Verification of DAS involves light nodes randomly selecting a unique set of coordinates and requesting the corresponding data chunks and Merkle proofs. Once validated, the data chunks and their accurate Merkle proofs are broadcasted throughout the network. As long as enough data chunks are collectively sampled, full nodes can reconstruct the entire block of data, maintaining data integrity and ensuring the smooth functioning of the network. Celestia's approach is innovative, efficient, and reliable.
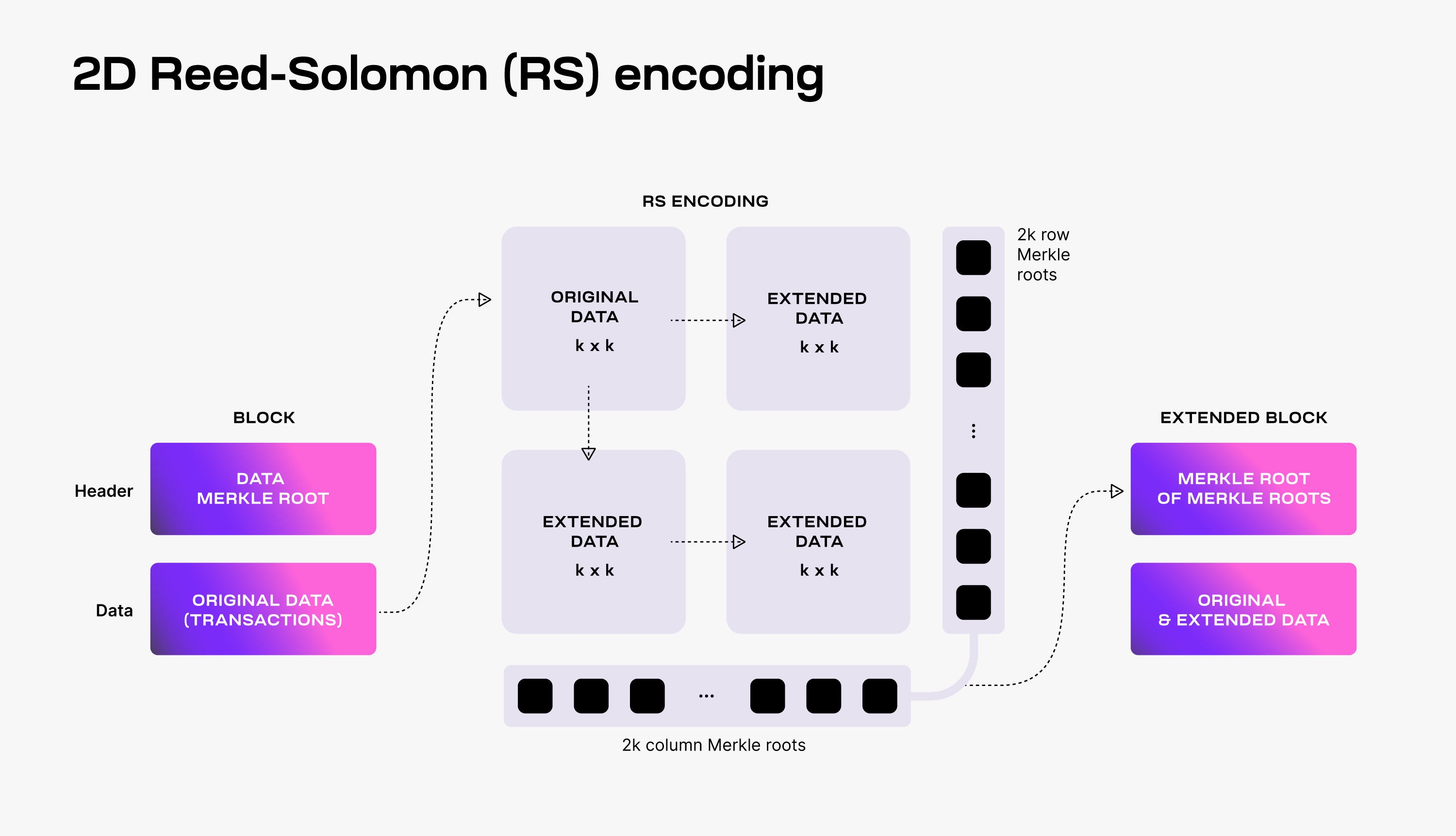
(Source: Celestia's data availability layer | Build Modular.)
2.1.2 Namespaced Merkle Trees
enable execution and settlement layers on Celestia to download transactions that are only relevant to them
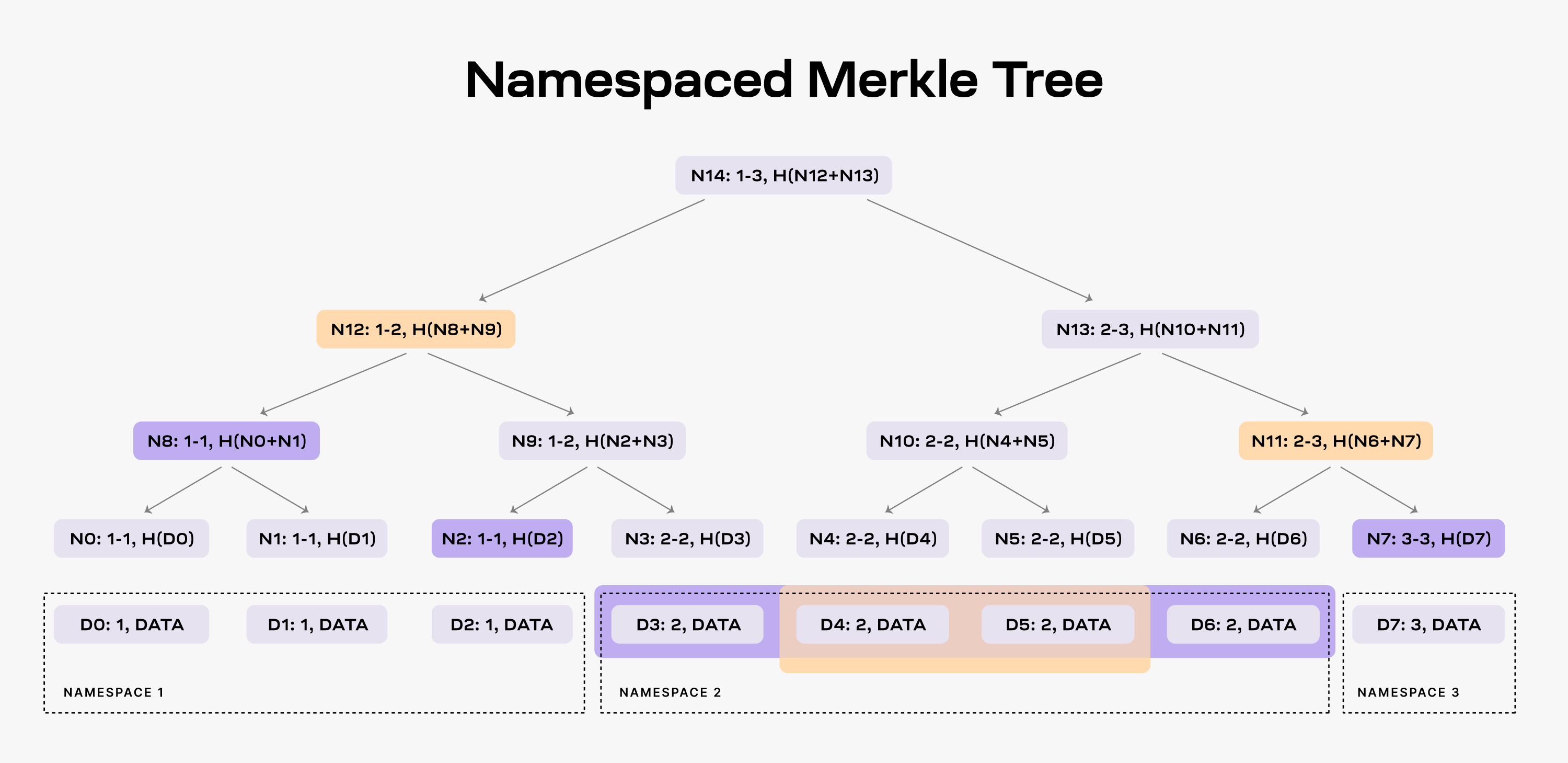
In Celestia, the block data is divided into several sections, known as namespaces. Each namespace corresponds to a specific application, such as a rollup, that uses the Data Availability (DA) layer. This system allows each application to focus only on its relevant data, ignoring the data linked to other applications.
However, for this setup to function, the DA layer needs to prove that all necessary data for a given namespace is included. To achieve this, Celestia uses a special tool known as Namespaced Merkle Trees (NMTs).
Think of an NMT as a kind of organized file system. It's a tree structure with leaves arranged according to the namespace identifiers. Moreover, it has a unique hash function in which every node in the tree contains a record of the range of namespaces for all its children. Consider an NMT with three levels (eight data segments), with data divided into three namespaces.
So, when an application requests data for namespace 2, the DA layer must provide the data chunks D3, D4, D5, and D6, along with nodes N2, N8, and N7 as evidence (note that the application already has the root N14 from the block header).
By providing this, the application can verify that the data is part of the block data, and also ensure that all the data for namespace 2 is present. If, for example, the DA layer only provides data chunks D4 and D5, it must also supply nodes N12 and N11 as proofs. The application can then identify that the data is incomplete by checking the namespace range of the two nodes, i.e., both N12 and N11 have descendants that are part of namespace 2.
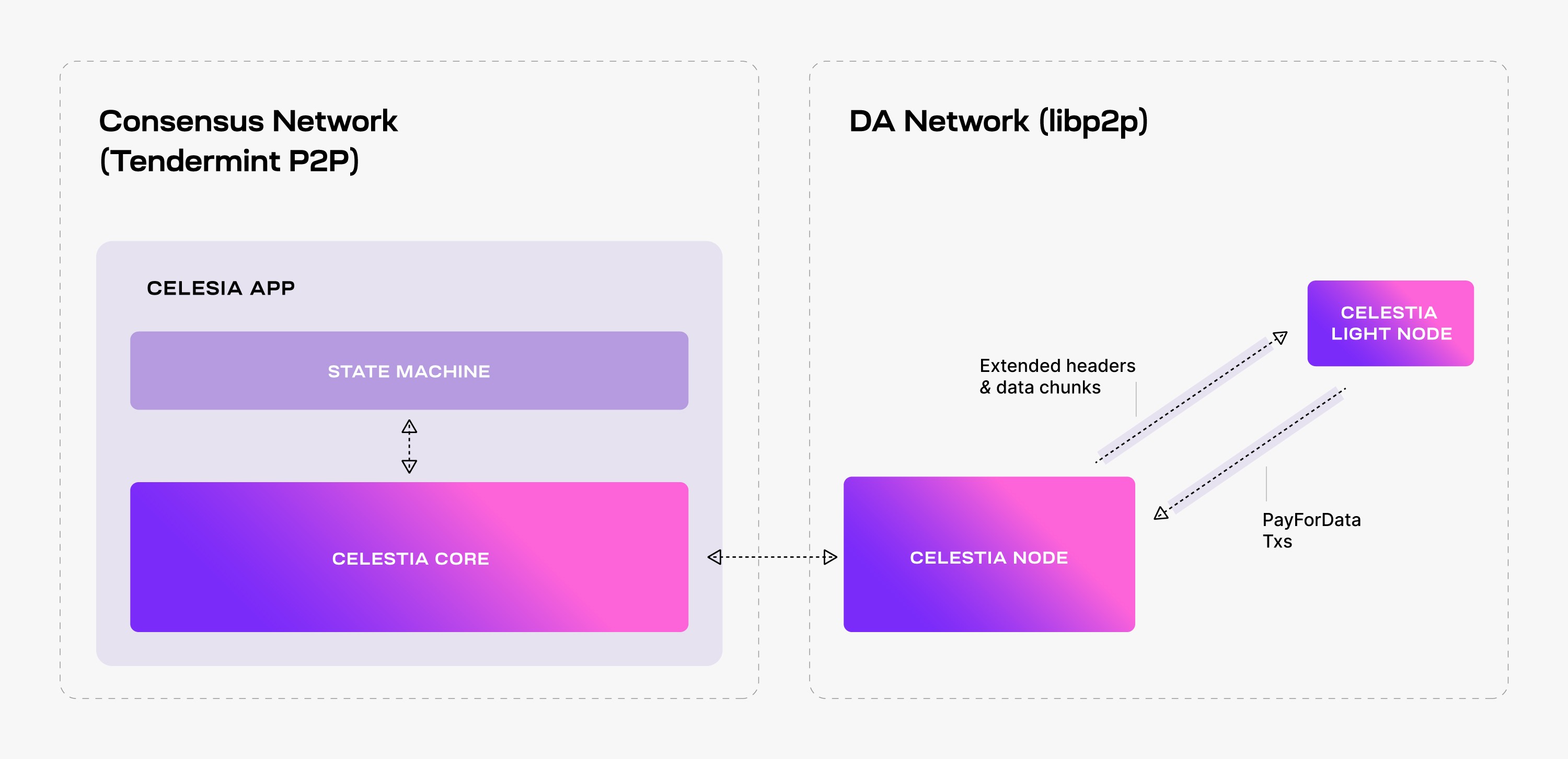
2.2 Architecture
Types of Nodes in Celestia Blockchain:
Consensus:
- Validator Node: Validator nodes play a crucial role in the consensus process by actively participating in block production and voting on proposed blocks.
- Full Consensus Node: This type of node, integrated within the
celestia-app, functions as a full node, responsible for syncing the complete blockchain history to ensure the integrity of the network.
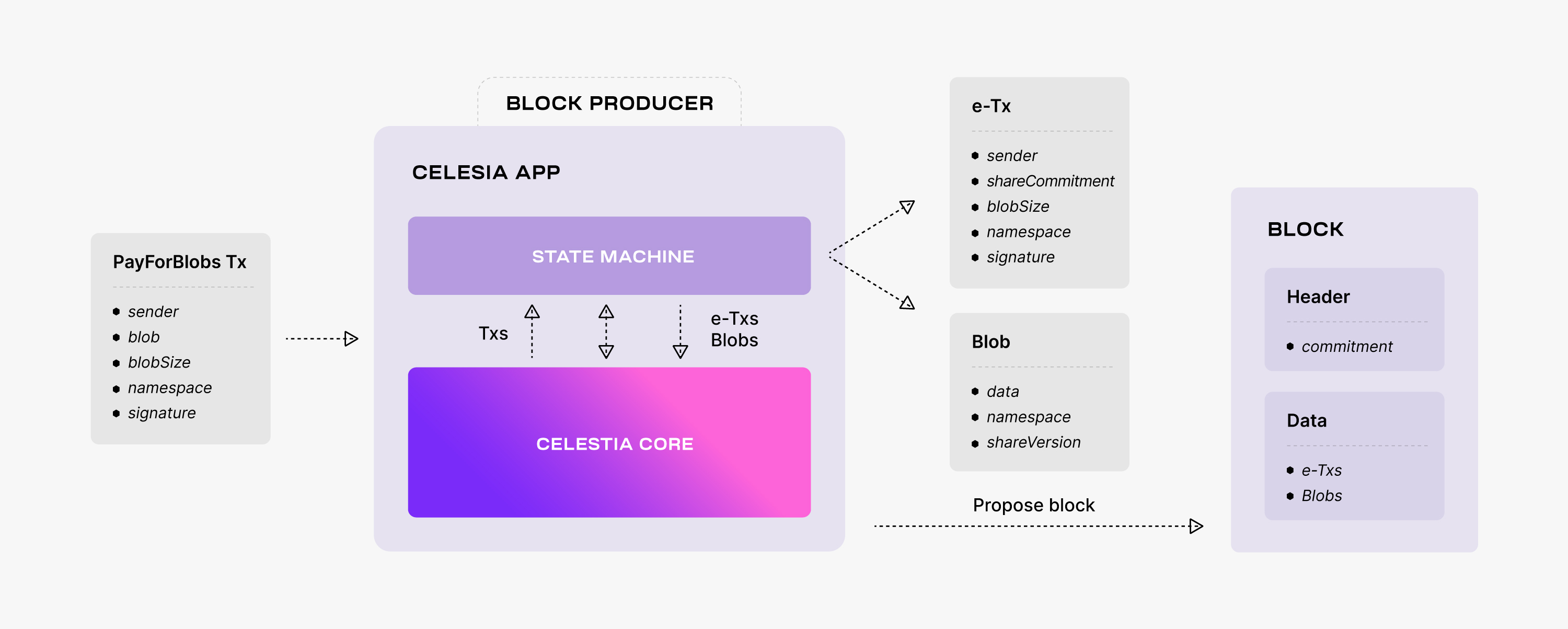
(Source: The lifecycle of a Celestia App transaction | Build Modular.)
Data Availability: Store data and provide proof for availability
- Bridge Node: The bridge node serves as a connection point between the Data Availability network and the Consensus network, facilitating the smooth transfer of blocks between the two.
- Full Storage Node: Full storage nodes are responsible for storing all the data related to the blockchain. However, unlike the Validator nodes, they do not participate in the consensus mechanism.
- Light Node: Light nodes act as clients that perform data availability sampling exclusively on the Data Availability network. Their primary purpose is to efficiently access necessary data without being directly involved in the consensus process.
(Source: The lifecycle of a Celestia App transaction | Build Modular.)
3. Use Cases
3.1 OP-Stack
By employing Celestia in the role of a DA layer, current L2s have the ability to shift from the traditional practice of uploading their data as calldata on Ethereum, and instead upload it to Celestia. The block's commitment gets recorded on Celestia, a platform specifically designed for data accessibility. This approach proves to be more scalable compared to the conventional method of uploading such data as calldata on large-scale, uniform chains.
3.2 Rollkit
Ethermint (EVM) rollup | Rollkit
Nodes in the rollup sequencer gather transactions from various users, compile these into blocks, and then utilize a data availability layer, like Celestia, for the blocks to be sequenced and finalized. The primary duty of full nodes involves execution and validation of the rollup blocks, with optimistic rollups specifically generating and distributing fraud proofs as necessary. Light clients, on the other hand, are responsible for receiving headers, validating different types of proofs (including fraud, zk, etc), and certifying queries related to the state that are minimally reliant on trust.
3.3 Sovereign Labs
https://github.com/Sovereign-Labs/sovereign-sdk/tree/main/examples/demo-rollup#demo-rollup
4. Team
- Mustafa Al-Bassam (CEO)
- Ismail Khoffi (CTO)
- John Adler (CRO)
- Nick White (COO)
5. Resources
- Website | Docs | Blog |Twitter
- Fraud and Data Availability Proofs: Maximising Light Client Security and Scaling Blockchains with Dishonest Majorities by Mustafa Al-Bassam, Alberto Sonnino, Vitalik Buterin
- The lifecycle of a Celestia App transaction by Celestia
- Overview to running nodes on Celestia by Celestia